- 8 (812) 612-97-27
- СПБ, Курчатова дом 1А помещение 1Н
- order@das-elektro.de

ЗАДАЧИ ПО ОБЕСПЕЧЕНИЮ СИНХРОНИЗАЦИИ В ПРОМЫШЛЕННЫХ ПРИЛОЖЕНИЯХ
В статье рассматриваются вопросы синхронизации сети управления промышленным оборудованием при передаче команд и данных. Оцениваются последствия задержки передачи данных, возникающей в сети, на работу промышленных механизмов. Предлагаются решения, минимизирующие задержку.
Введение
В промышленной робототехнике и станках для выполнения поставленной задачи осуществляется точное и скоординированное перемещение механизмов по нескольким осям в пространстве. Роботы обычно имеют шесть степеней свободы, перемещение механизмов по которым должно быть скоординированным, а иногда и семь, если робот движется по рельсам. В станках с ЧПУ обычно используются пять степеней свободы, хотя есть и такое оборудование, где используется до 12 осей, в соответствии с которыми инструменты и заготовки перемещаются друг относительно друга в пространстве. Каждая ось предполагает наличие сервопривода, двигателя, а иногда и редуктора между двигателем и осевым шарниром или рабочего инструмента манипулятора. Кроме того, система, как правило, имеет сетевое подключение по промышленному протоколу Ethernet в соответствии с линейной топологией, как показано на рисунке 1. Контроллер механизма преобразует требуемую пространственную траекторию в значения положения для каждой серво оси, которые передаются по сети в циклическом режиме.
Цикл управления
Такое оборудование работает с определенным временем цикла, которое обычно равно или кратно циклу переключения режима управления или широтно-импульсной модуляции (ШИМ) привода серводвигателя. Задержка передачи информации одним концом сети другому в этом случае является ключевым параметром (см. рис. 2). В течение каждого периода цикла новое значение положения и прочая соответствующая информация должны передаваться от контроллера механизма к каждому узлу, как видно из рисунка 1. В цикле ШИМ для каждого узла должно быть достаточно времени, чтобы обновить расчет алгоритма сервоуправления с использованием нового значения положения, а также любых новых данных, полученных от датчиков. Затем каждый узел записывает в сервопривод обновленный вектор ШИМ в один и тот же момент времени с помощью механизма распределения сигналов синхронизации, который зависит от протокола для промышленных Ethernet-сетей. В зависимости от архитектуры управления часть алгоритма контура управления может быть реализована в ПЛК. В этом случае система потребует достаточного количества времени, чтобы обеспечить дальнейший доступ к функционированию после получения по сети любой новой актуальной информации от датчиков.
Рисунок 1
Рисунок 2
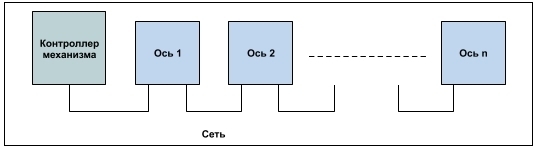
Сетевая топология многоосевого механизма
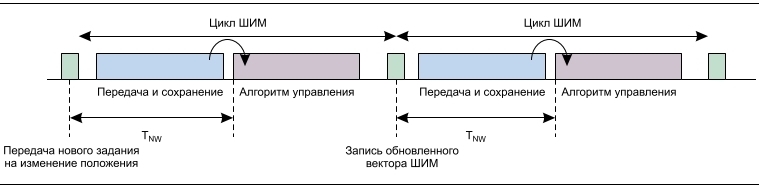
Цикл ШИМ и время передачи данных по сети
Рисунок 3
Рисунок 4
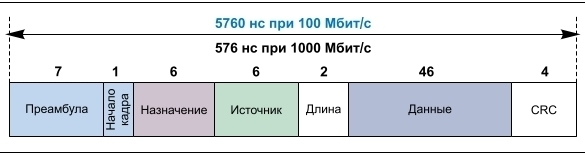
Задержка полосы пропускания Ethernet-кадра минимальной длины
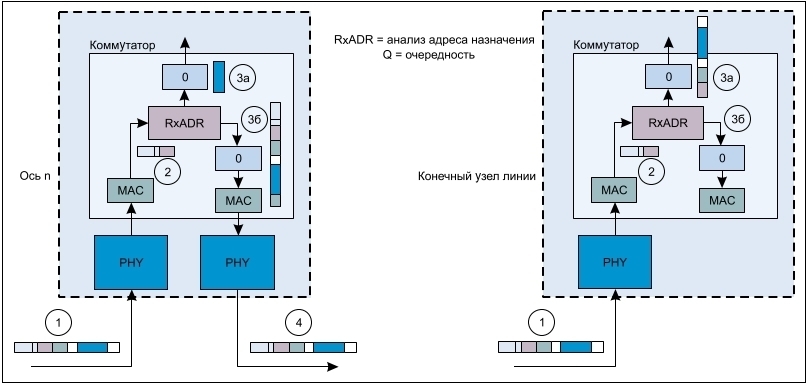
Задержки кадра: а) задержки кадра 2-портового узла; б) конечного узла линии
Рисунок 5
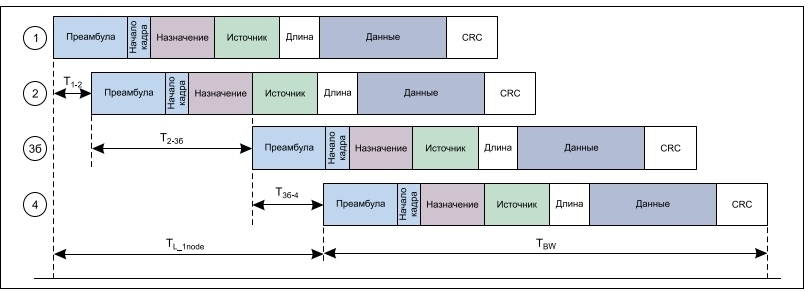
Временная шкала передачи кадров
Задержка передачи данных
Если предположить, что единственным трафиком в сети станут циклические данные, передаваемые между контроллером механизма исервоузлами, сетевая задержка (TNW) будет определяться количеством сетевых переходов до самого дальнего узла, скоростью передачи данных в сети и задержками в каждом узле. В случае с робототехническим оборудованием и станками задержкой распространения сигнала по проводу можно пренебречь, поскольку длина кабеля в таком случае, как правило, относительно мала. Основной задержкой является задержка полосы пропускания, т. е. время для передачи данных по сетевому кабелю. Для Ethernet-кадра минимального размера (который свойственен системам управления станками и роботами) задержка полосы пропускания для скоростей передачи 100 Мбит/с и 1 Гбит/с показана на рисунке 3. Ее величина определяется частным от деления размера пакета на скорость передачи данных. Стандартный набор полезных данных многоосной системы, передаваемый от контроллера к сервоприводу, состоит из 4-байт значения скорости/положения и 1-байтуправляющего словадля каждого сервопривода, т. е. для робота с шестью степенями свободы этот набор данных состоит из 30 байт. Конечно, в некоторых случаях потребуется больше обновленной информации, или оборудование получит большее количество степеней свободы. Тогда потребуются пакеты, размер которых может превыситьминимальный.Задержка в полосе пропускания может вырасти за счет задержек при прохождении Ethernet-кадра через микросхемы физического уровня (PHY) и 2-портовый коммутатор в каждомсервосетевоминтерфейсе. На рисунках 4–5 показано прохождение кадра по PHY-уровню в подуровень MAC (1–2) и далее через систему анализа адреса назначения, где должны быть синхронизованы только элементы преамбулы и назначения кадра. На пути 2–3a извлекается полезный набор данных для текущего узла, а по пути 2–3б осуществляется дальнейшее прохождение кадра к конечному узлу или узлам. На рисунке 4a представлен только набор полезных данных, передаваемый приложению по пути 2–3a, тогда как на рисунке 4б показана передача практически всего кадра. Видны небольшие различия, которые возникают между протоколами Ethernet. На пути 3б–4 происходит передача кадра через очередь передачи, PHY и обратно по проводу. Этого пути нет у конечного узла линии, как видно из рисунка 4б. В данном случае предполагается сквозная пакетная коммутация, а не буферизованная, которая имеет гораздо более высокую задержку, поскольку весь кадр до его дальнейшей отправки синхронизуется в коммутаторе. Элементы задержки кадра на временной шкале представлены на рисунке 5, гдепоказано общеевремя передачи кадра через один узел оси. TBW представляет собой задержку полосы пропускания, а TL_1node –задержку кадра через один узел. Помимо задержек, связанных с физической передачей битов по проводам и синхронизацией адресных битов для анализа адреса назначения, другими элементами, которые влияют на задержки передачи в системе, являются задержки на уровне PHY и компонентов коммутатора. По мере увеличения скорости передачи данных по проводной сети и роста количества узлов эти задержки становятся еще более важным фактором, определяющим характер полной задержки передачи кадров от одного конца сети к другому.
Решения с низкой задержкой
Analog Devices недавно выпустила две новых микросхемы PHY промышленного Ethernet, предназначенные для надежной работы в жестких условиях с расширенным диапазоном температур до 105C и обладающие наименьшим в отрасли энергопотреблением и задержкой. ADIN1300 и ADIN1200 предназначены для решения задач, описанных в этой статье, и стали идеальным вариантом для применения в промышленном оборудовании. С учетом многопротокольного встраиваемого 2-портового коммутатора fido5000 для сетей Ethernet реального времени компания Analog Devices обладает полным ассортиментом решений для создания детерминированных чувствительных ко времени сетей. Задержки, вносимые микросхемой PHY и коммутатором, приведены в таблице. В данном случае предполагается, что система анализа приемного буфера определяет адрес назначения, а скорость передачи данных по сети составляет 100 Мбит/с. В качестве примера просуммируем эти задержки для линейной сети 7-осевой системы и предусмотрим синхронизацию полного набора полезных данных в конечном узле (как на изображении 3a рисунка 4). В результате получим следующую полную задержку передачи: 6TL_1узел + TBW + Tузел7 = 6 ∙ (248 нс + + 330 нс + 1120 нс + 52 нс) + 5760 нс + + (248 нс + 1120 нс + 58 ∙ 80 нс) = = 22,3 мкс. Произведение 58 ∙ 80 нс представляет собой оставшиеся 58 байт набора полезных данных после прочтения байтов преамбулы и адреса назначения. Этот расчет предполагает, что в сети нет другого трафика или наивысший приоритет имеет чувствительный ко времени трафик. Расчет также в некоторой степени зависит от протокола, поскольку в зависимости от конкретного используемого промышленного протокола Ethernet в вычислениях могут быть небольшие изменения. Но вернемся к рисунку 2. В системе управления механизмом с длительностью цикла 50–100 мкс передача кадра в самый дальний узел может занимать почти 50% цикла, сокращая тем самым время, доступное для обновления данных управления двигателем и алгоритма управления движением для следующего цикла. Сведение к минимуму этого времени передачи является важным фактором для оптимизации скорости работы системы, т. к. позволяет проводить более длительные и сложные вычисления алгоритма управления. Учитывая, что задержки, связанные с передачей данных по кабелю, являются фиксированными и связаны со скоростью прохождения битов, использование компонентов с низкой задержкой, например микросхемы физического уровня ADIN1200 и встраиваемого коммутатора fido5000, является ключом к оптимизации скорости работы системы, особенно при увеличении количества узлов (например, в случае со станком сЧПУс 12 степенями свободы) и сокращении времени цикла. Переход нагигабитныйEthernet значительно снижает влияние задержки полосы пропускания, но увеличивает долю общей задержки, вносимой коммутатором и микросхемами PHY. Например, задержка передачи станка с ЧПУ и 12 степенями свободы вгигабитнойсети составит около 7,5 мкс. В данном случае элемент задержки, связанный с полосой пропускания, пренебрежимо мал; при этом не имеет большого значения, каков размер кадров Ethernet, – минимальный илимаксимальный.Сетевая задержка распределяется примерно поровну между микросхемами PHY и коммутаторами, что подчеркивает важность минимизации задержки в этих элементах, поскольку все больше промышленных систем переходят нагигабитныескорости, сокращается время цикла управления (стандарт Ether CAT предусматривает время цикла 12,5 мкс), и возрастает количество узлов за счет подключения датчиков к Ethernet-сети.
Таблица
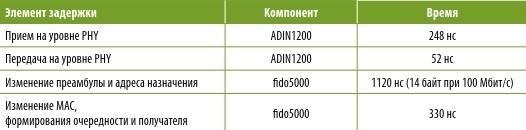
Задержки, вносимые микросхемой PHY и коммутатором
Вывод
В высококачественном многоосном промышленном оборудовании с синхронизованным движением механизмов требуется точность синхронизации, детерминированность и высокая чувствительность ко времени; при этом необходимо обеспечить наименьшую задержку передачи данных от одного конца сети к другому, поскольку время цикла управления в таких системах постоянно сокращается, а сложность алгоритма управления возрастает. Характеризующиеся низкой задержкой микросхемы PHY и встраиваемые коммутаторы являются важными элементами оптимизации работы этих систем. Для решения задач, описанных в данной статье, компания Analog Devices недавно выпустила две новых надежных микросхемы физического уровня промышленного Ethernet ADIN1300 (10/10 0 Мб и т/1 Гб и т) и AD I N120 0 (10/100 Мбит)
Корзина пуста
0
шт.
/
$0
Оформить
Очистить